deepeval.com 建站模板测评
开源LLM评测框架
⚡ 评分构成
各维度得分依据公开资料与字段推算,加权后即综合评分,仅供参考。
- 工程化形态清晰,适合把 LLM 质量评测纳入自动化测试和发布流程
- 指标覆盖面广,包含 RAG、对话、毒性、偏见、忠实度等常见场景
- 支持执行 trace,可定位 Agent、Retriever、Tool、LLM 等组件问题
- 支持多种主流模型提供商、编排框架和向量数据库
- 可生成合成测试集,降低早期缺少真实用户数据时的评测门槛
- 正文未披露价格、免费额度、企业版细节或服务 SLA
- LLM-as-a-Judge 仍依赖评审模型质量、成本和稳定性,需要团队自行校准
- 中文支持未明确说明,中文评测效果需结合所选评审模型和自定义指标验证
- 对非工程团队不算低门槛,更偏开发者和测试流水线场景
深度测评
是什么
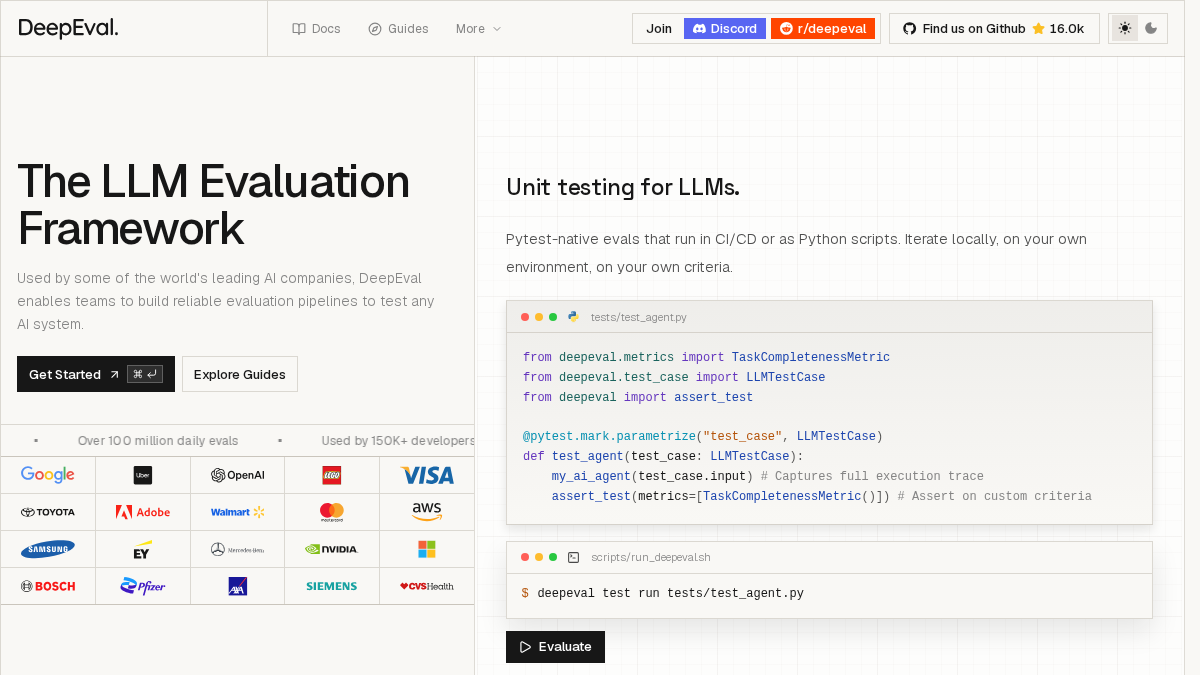
DeepEval 是一个面向 LLM 应用和 AI Agent 的评测框架,定位类似“LLM 的单元测试”。它支持以 pytest-native 的方式在本地、Python 脚本或 CI/CD 中运行评测,适合把模型输出质量、RAG 效果和 Agent 行为纳入工程发布流程。正文提到其被大量开发者和企业使用,但未给出可核验的客户清单或案例细节。
核心能力
在 AI 能力上,DeepEval 提供 LLM-as-a-Judge 评测,并内置 50+ research-backed metrics,覆盖幻觉、忠实度、答案相关性、摘要、毒性、偏见等常见质量维度。它还支持多轮对话评测,如角色遵循、知识保持、对话完整性,并将文本、图像、音频作为一等模态处理。评测方法包括 G-Eval、DAG 和 QAG,可通过自然语言标准、决策图和加权评分构建更贴近业务的指标。
API、集成与数据
DeepEval 的工程集成是亮点:可通过 CLI、Python、pytest 和 CI/CD 使用,并能追踪 Agent 执行链路,对 AGENT、RETRIEVER、TOOL、LLM 等节点分别打分。集成覆盖 LangChain、LangGraph、LlamaIndex、CrewAI、OpenAI Agents、Pydantic AI 等框架,评审模型可接入 OpenAI、Anthropic、Gemini、DeepSeek、Moonshot、Ollama、vLLM 等;向量数据库支持 Chroma、Weaviate、Qdrant、PGVector、Elasticsearch 等。隐私方面,正文只提到可在自己的环境中本地迭代,以及可按隐私需求选择模型提供商,未披露加密、数据保留或合规认证。
定价与中文支持
抓取正文未披露免费额度、试用、定价套餐或支付方式。中文支持也未明确说明;考虑到它支持 DeepSeek、Moonshot 等模型,中文评测能力可能取决于所选 judge 模型与自定义指标,但不能视为官方承诺。
优缺点与适合人群
优点是指标体系全面、可解释打分、trace 级定位能力强,并能生成合成 golden 数据与模拟对话,适合缺少真实用户数据的早期阶段。局限是 LLM-as-a-Judge 本身受评审模型、阈值和测试集质量影响;同时产品更偏开发者工具,非工程团队上手成本较高。它尤其适合 LLM 应用团队、RAG 团队、AI Agent 团队和需要质量回归门禁的企业研发。
中国访问
正文没有提供中国大陆访问、网络可用性或支付信息,因此判断为未知。若访问、支付或海外模型调用受限,可对比 Ragas、Promptfoo、TruLens、LangSmith、Arize Phoenix、OpenAI Evals 等替代方案,并优先选择可接入本地模型或国内模型供应商的部署方式。
本测评基于公开资料整理,不构成购买建议,请以 deepeval.com 官网实际信息为准。
中文卖点
AI应用测试评估利器,适合RAG/Agent。
官网快照
价格走势
用户评价
评分明细(分布与用户短评)接入中。当前展示 TG4G 综合评分,数据源自公开测评与用户反馈。