C
🤖 AI 应用
PDF抽取引用验证API 未知总部 国内优化
citellm.com AI 应用测评
为LLM输出加PDF引用
数据来源
ai_crawl · 最近更新 2026-07-01
行业深度解析AI 深度分析
一句话支持精准溯源引用的文档结构化数据提取API,解决LLM输出信任问题
定价按月订阅+按使用量阶梯计费 Starter套餐99美元/月,约0.10美元/页,每月含1000页额度,提供Cloud API与基础支持
适合谁受监管行业开发人员、文档审核团队、审计合规人员、AI工具构建者
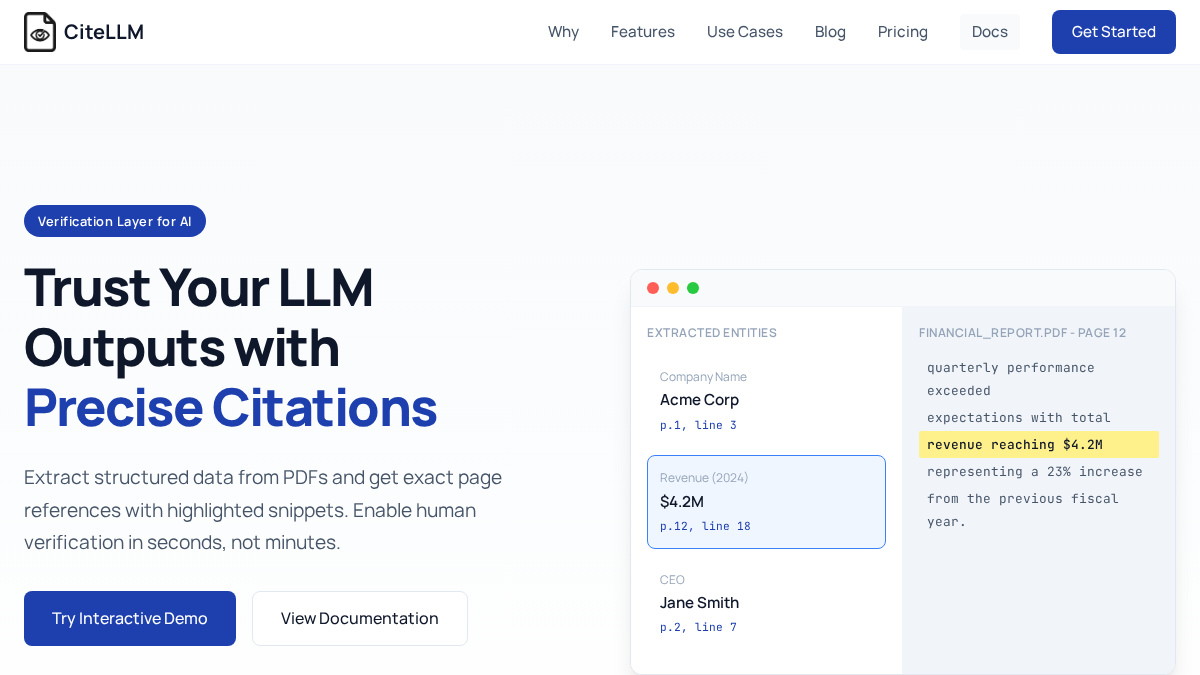
核心功能每提取字段附带精确页码、文本 bounding box 与来源片段点击提取实体可直接跳转至PDF对应位置并高亮来源支持自托管部署,敏感数据无需流出自有基础设施简单API集成:提交PDF与提取JSON schema即可返回带引用的结构化数据提供React/JS嵌入式组件,快速接入侧栏验证UI每个提取结果附带置信度分数,辅助标注需人工审核的边缘案例
AI能力与模型CiteLLM用于从PDF中按用户提供的JSON Schema抽取结构化数据,并为每个字段生成页码、bounding box、source snippet和confidence score。文本强调其定位不是单纯LLM抽取,而是给LLM输出增加验证层;未披露具体底层模型、OCR引擎或训练方式。
典型用例适用于M&A尽调、贷款承保、合同分析、保险理赔、SEC/监管文件分析、发票抽取等。核心场景是长PDF或多文档工作流中,需要证明每个数字、条款或结论来自哪里,并支持人工复核和审计。
免费额度/试用页面未显示免费额度或公开试用。主要入口为Request Access、Schedule Demo和Get API Key。
定价Starter 99美元/月,1,000页/月,约0.10美元/页;Growth 499美元/月,8,000页/月,约0.06美元/页,额外页0.08美元/页;Enterprise定制,支持自托管、本地部署、定制集成和专属支持。
中文支持API options中有language字段,默认auto,表示可传入文档语言提示或自动识别。但文本没有明确说明中文界面、中文文档抽取质量、中文OCR或中文客服支持。
API与集成提供REST API,Base URL为https://api.citellm.com,主要端点包括POST /v1/extract、POST /v1/documents、GET/DELETE documents、GET extractions。支持Bearer Token认证,Python、Node.js、cURL、Go示例;Growth包含Widget SDK,页面说明有React/JS嵌入组件。
数据隐私云API可直接使用;企业版支持Docker自托管、on-premise、air-gapped support和full data sovereignty,宣称敏感文档可不离开用户基础设施。文档也支持删除document及关联extractions。未看到更细的加密、数据保留期限或合规认证说明。
输出质量与局限输出包含置信度,文档给出0.95以上高置信、0.85-0.94中等、0.70-0.84低置信、0.70以下建议人工抽取的解释,并支持confidence_threshold过滤。局限在于抽取仍可能有低置信或不确定结果,需要human-in-the-loop;网站未提供独立基准测试、准确率指标或复杂版式失败案例。
支付['']
中国访问未知
国内可用性🔎 查任意海外服务在中国能不能用 →
适用场景['金融科技与贷款场景提取、验证收入等关键财务数据''受监管行业的合规文档结构化与审计追溯''企业内部大量PDF文档的可信结构化提取''AI文档工具的信任层搭建,提升用户采纳率']
同类Google Document AI、AWS Textract、Azure AI Document Intelligence、Rossum、Mindee、Unstract、LlamaParse
性价比7
易用8
服务7
综合8
优点
- 无需针对用户自有文档训练模型,开箱即用
- 处理完成后自动删除上传文件,兼顾云部署数据安全
- 人工审核效率提升显著:从数分钟手动翻页缩短至10秒内点击验证
- 自动留存审核轨迹,满足审计合规要求
不足
- 暂仅支持PDF格式文档提取,未覆盖Word等其他办公格式
- 公开的基础版定价仅披露Starter层级,企业级定制方案未明确
- 目前抓取内容未提及多语言支持范围,中文文档提取效果未知
📢 订阅 TG4G 电报频道
每日精选全球资源 + 国内可用性速报 · 也可在 @amzseo_bot 直接搜
中文卖点
解决AI幻觉核验,适合法务金融文档场景。
官网快照
价格走势
价格未公开
当前定价
价格采集自官网公开页面,实时更新;历史走势数据采集中,暂无足够历史样本。下单请以官网实时价为准。
用户评价
8.0/10
TG4G 综合评分
评分明细(分布与用户短评)接入中。当前展示 TG4G 综合评分,数据源自公开测评与用户反馈。
常见问题
citellm.com 是一家未知的AI 应用 (PDF抽取引用验证API)服务商. 本页收录其「为LLM输出加PDF引用」套餐. 解决AI幻觉核验,适合法务金融文档场景.
citellm.com 在中国大陆有较好的直连体验, 多数地区无需代理即可访问. 该商家总部位于未知, 主要面向海外市场.
访问 citellm.com 官网完成注册即可使用. 注册一般需要邮箱 (推荐 Gmail/Outlook) 和支付方式. 多数海外服务支持信用卡 / PayPal / 加密货币. 完整流程见本页"前往官网"按钮.
浏览其他大类
🌾 农业食品
🔗 API 数据
🚪 API 网关
🧊 3D素材
🚗 汽车出行
🗃 备份容灾
📋 公司合规
📡 智能盒子
🧱 建站模板
🌐 CDN
💬 聊天 App
☁ 网盘云盘
📖 漫画网文
✉ 通讯邮箱
🏢 跨国名企
💰 加密
🗄 托管数据库
🏷 比价优惠
🎨 设计创意
🔧 开发工具
📡 DNS 解析
🌍 域名
⬇ 下载软件
🛒 电商
📚 教育课程
📧 邮件发送
⚡ 能源环保
🎫 活动票务
🎪 会展展会
📤 文件传输
🏦 金融钱包
📝 表单调研
💭 论坛社区
💸 众筹融资
🎮 游戏服务
🎮 游戏市场
🕹 游戏平台
🎁 订阅礼品卡
🏛 政府机构
🎯 GPU 算力
🔌 硬件 IoT
🩺 医疗健康
👔 招聘远程
🖼 图片灵感
🛡 保险
💼 求职招聘
📒 知识笔记
⚖ 法务财税
📍 本地生活
📦 物流货运
🔎 生活查询
🗺 地图导航
📈 营销 SEO
📺 流媒体订阅
🎞 家庭影音
📰 新闻资讯
🤝 公益慈善
📄 办公协作
🌍 国际组织
☁ 应用部署
🎛 主机面板
🔑 密码安全
💳 支付
🐾 宠物
👕 印刷定制
🎙 播客有声
🔌 代理
❓ 问答内容
🏠 房产租售
⚡ 实时通信
🖥 远程桌面
🗂 资源站
⚙ SaaS
♻ 二手交易
🛡 安全
📱 短视频直播
📲 接码虚拟号
💬 社交约会
🔐 SSL 证书
💾 云存储
🎓 留学教育
🎧 在线客服
🧰 在线工具
🌐 翻译本地化
✈ 旅游出行
🏛 全球大学
🚀 加速器 VC
▶ 视频平台
🎬 视频托管
🔒 VPN 隐私
🖥 服务器
🌐 虚拟主机
🔏 零信任组网