ceobench.com AI 应用测评
AI智能体经营基准
⚡ 评分构成
各维度得分依据公开资料与字段推算,加权后即综合评分,仅供参考。
- 填补了当前AI测试领域仅测单任务能力、缺乏长期战略决策能力测试的空白
- 场景设计贴近真实企业运营逻辑,包含不确定性、信息延迟、动态竞争等真实挑战
- 学术背景可靠,项目完整开源代码、论文和测试轨迹
- 动作空间设计灵活,支持AI智能体组合出丰富多样的决策策略
- 目前仅为学术基准测试项目,未面向商业落地提供可直接使用的AI掌舵产品
- 模拟场景仍为简化抽象,无法完全还原真实企业运营的所有复杂变量
- 普通用户无直接可用的商业化服务,仅对研究群体开放价值
深度测评
是什么
CEO-Bench是普林斯顿大学研究团队推出的AI基准测试项目,核心目标是填补当前AI测试领域的空白:现有AI大多只测试单个任务(比如编码、写作)的完成能力,而CEO-Bench专注于衡量AI面向长期组织目标的「掌舵智能(Steering Intelligence)」——也就是类似企业CEO带领组织穿越不确定性、达成长期目标的战略决策能力。该项目目前开源了代码、测试论文和模型测试轨迹数据,供全球AI研究团队使用。
核心功能与测试逻辑
CEO-Bench的核心测试场景是让AI智能体模拟运营一家AI初创公司500天,初始拿到100万美元启动资金,最终以结束时的现金余额作为核心性能指标。测试覆盖掌舵能力的四个核心维度:长周期不确定性应对、噪声环境下的信息获取、动态环境下的策略调整、多模块协同对齐长期目标。
整个测试框架还原了大量真实商业细节:一共设置26个客户细分群体,初始仅可见6个,AI需要付费开展市场研究才能发现剩余用户;AI可调用34类结构化工具完成日常决策,包括查询19个业务SQL数据库做数据分析、定价、产品研发投入、营销获客、社交媒体运营等,每个工具支持细粒度参数调整,可组合出海量决策空间;市场带有动态竞争机制,竞争者会持续拉高用户的质量预期,迫使AI持续投入研发;用户满意度会通过模拟社交媒体传播,影响细分市场声誉和后续获客效果,完全符合真实商业的反馈逻辑。
定价与 accessibility
该项目本身是学术开源项目,代码、测试数据均免费开放,页面中的价格数字仅为不同模型模拟运营后的最终现金余额测试结果,并非平台服务定价,无收费门槛。
优缺点分析
优点方面,它开创性地提出了下一代AI能力的测试方向,填补了行业空白;场景设计贴近真实商业决策的复杂性,引入了信息不对称、动态竞争、结果延迟等真实挑战;项目完全开放,所有研究团队都可以用它做能力对标。缺点则是目前仅为学术研究基准,并非可直接使用的商业化产品,普通用户无法直接使用;模拟场景仍然是抽象简化后的结果,无法覆盖真实企业运营的所有复杂变量。
适合人群与中国访问
该项目仅适合AI大模型研究人员、AI智能体开发团队、企业战略方向AI的研究机构使用,普通用户几乎没有使用需求。抓取内容未明确验证中国访问状态,无法确认连通性。
本测评基于公开资料整理,不构成购买建议,请以 ceobench.com 官网实际信息为准。
中文卖点
普林斯顿AI创业模拟基准,含代码论文轨迹。
官网快照
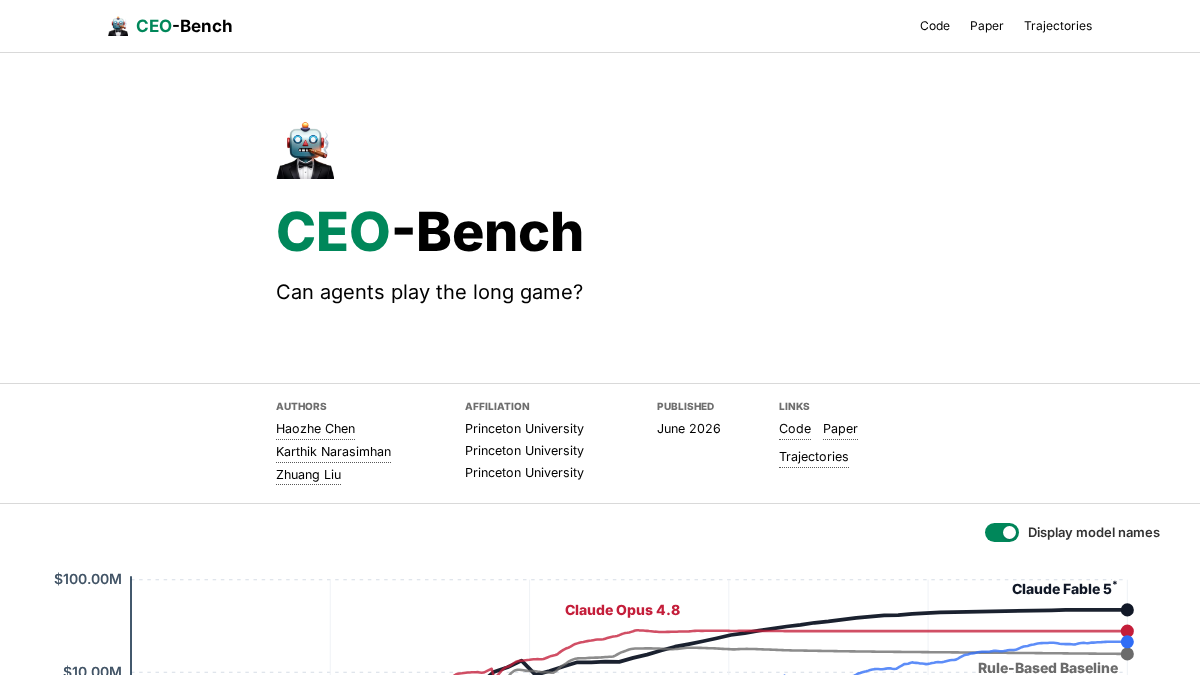
价格走势
用户评价
评分明细(分布与用户短评)接入中。当前展示 TG4G 综合评分,数据源自公开测评与用户反馈。